Cijfers zorgvraagtypering NZa tonen onthutsend onnauwkeurig beeld
 In het recente advies aan de Nederlandse Zorgautoriteit(NZa) door de adviescommissie zorgvraagtypering van 9 februari 2024 staan zestien pagina’s vol met grafieken en tabellen. Deze heeft de NZa aan de adviescommissie verstrekt om duidelijk te maken hoever ze is met de ontwikkeling van het nieuwe bekostigingsmodel voor de GGZ: het zorgprestatiemodel. De grafieken en tabellen berusten op de eerste verwerkingen van verplicht door GGZ-zorgaanbieders aangeleverde data, waaronder de antwoorden op HONOS-vragenlijsten. Het totaal aantal mensen waarover de NZa de toezending verplicht stelde besloeg 800.000 personen. De NZa blijkt de data van ongeveer 500.000 cliënten ontvangen te hebben. Ze denkt nog wel meer dan dat binnen te krijgen, maar het ontbrekende deel kan zeer wel op het conto staan van bezorgde zorgaanbieders die wakker geworden zijn door de actiegroep Vertrouwen in de GGZ. Deze groep van cliënten, zorgaanbieders en sympathiserende instituties en individuen verzet zich fel tegen genoemde dataverzameling.
In het recente advies aan de Nederlandse Zorgautoriteit(NZa) door de adviescommissie zorgvraagtypering van 9 februari 2024 staan zestien pagina’s vol met grafieken en tabellen. Deze heeft de NZa aan de adviescommissie verstrekt om duidelijk te maken hoever ze is met de ontwikkeling van het nieuwe bekostigingsmodel voor de GGZ: het zorgprestatiemodel. De grafieken en tabellen berusten op de eerste verwerkingen van verplicht door GGZ-zorgaanbieders aangeleverde data, waaronder de antwoorden op HONOS-vragenlijsten. Het totaal aantal mensen waarover de NZa de toezending verplicht stelde besloeg 800.000 personen. De NZa blijkt de data van ongeveer 500.000 cliënten ontvangen te hebben. Ze denkt nog wel meer dan dat binnen te krijgen, maar het ontbrekende deel kan zeer wel op het conto staan van bezorgde zorgaanbieders die wakker geworden zijn door de actiegroep Vertrouwen in de GGZ. Deze groep van cliënten, zorgaanbieders en sympathiserende instituties en individuen verzet zich fel tegen genoemde dataverzameling.
Onthutsend onnauwkeurig
De opsomming van getallen begint op pagina 4 van het advies onder hoofdstuk 2 “Voorlopige bevindingen data-analyse”. Alle tabellen/grafieken hebben betrekking op de door de NZa gedefinieerde zorgvraagtypen. Dat mag men geen diagnosen noemen van de NZa maar de omschrijving van de verschillende zorgvraagtyperingen komen daar akelig dicht in de buurt. Het begint al goed met de tabel Gemiddelde kosten per zorgvraagtype in hoofstukje 2.1. Men toont daar de gem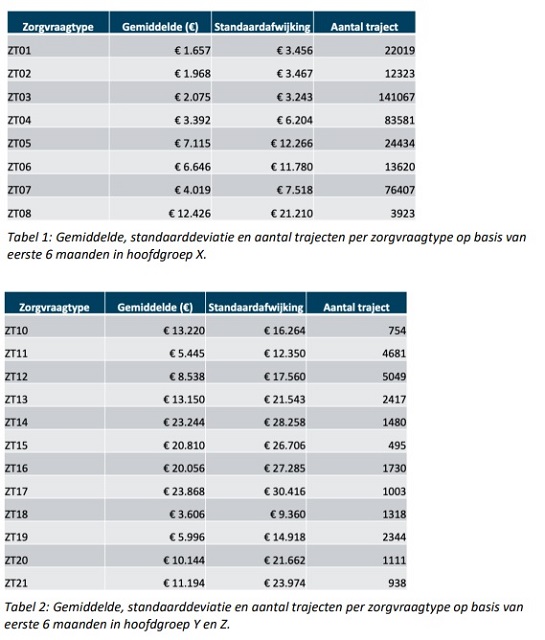 iddelde kosten(per cliënt, maar dat staat er niet bij) per zorgvraagtype. Er is een oplopend patroon zichtbaar in gemiddelde kosten bij oplopend zorgtypenummer, maar tegelijk zijn de standaardafwijkingen bijzonder groot. Voor een systeem dat bedoeld is om o.a. te om de totale GGZ-zorgkosten goed tevoren in te kunnen schatten(o.a. ten behoeve van de risicoverevening tussen zorgverzekeraars) is het bizar om te zien hoe de kosten voor meerdere zorgvraagtypen een standaardafwijking hebben die twee keer zo groot is als het gemiddelde.
iddelde kosten(per cliënt, maar dat staat er niet bij) per zorgvraagtype. Er is een oplopend patroon zichtbaar in gemiddelde kosten bij oplopend zorgtypenummer, maar tegelijk zijn de standaardafwijkingen bijzonder groot. Voor een systeem dat bedoeld is om o.a. te om de totale GGZ-zorgkosten goed tevoren in te kunnen schatten(o.a. ten behoeve van de risicoverevening tussen zorgverzekeraars) is het bizar om te zien hoe de kosten voor meerdere zorgvraagtypen een standaardafwijking hebben die twee keer zo groot is als het gemiddelde.
Geen normale verdeling
De standaardafwijking is een maat voor de nauwkeurigheid van data in een bepaalde groep. Hoe kleiner de standaardafwijking is des te nauwkeuriger zijn de metingen. Hoe groter hoe onnauwkeuriger. Wat ook opvalt is dat de standaardafwijking in ALLE groepen groter is dan het gemiddelde. Dat betekent ook dat de verdeling van de individuele meetpunten binnen de onderscheiden zorgvraagtyperingen geen “normale verdeling’’ kent zoals in een Gausse curve)(kerkklok-model). Immers als je kijkt naar de spreiding van de meetwaarden dan zie je dat het gemiddelde minus 1x de standaardafwijking op een negatief bedrag uitkomt. Het betekent heel simpel dat je als onderzoekende instantie je terdege af moet vragen of de gekozen systematiek met de HONOS-vragen als basis wel de juiste is.
NZa-redenering
De NZa mompelt dan nog wel dat de getallen wel iets kan zeggen over het instrument(de zorgvraagtypering met haar specifieke indeling) maar dat het ook aan de praktijkvariatie kan liggen.
Het totaal aantal zorgtrajecten waarover het berekend is bedraagt in totaal 396771.Het gaat dus over data van bijna 400.000 cliënten. Door middeling zal de praktijkvariatie hier echt wel uit zijn.
Geen rocket-science
Als u nu denkt dat ik hier rocket-science sta te verkondigen dan hebt u het mis. Het was leer-/oefenstof medische statistiek voor eerstejaars medicijnstudenten uit 1967. De getallen van de NZa laten gewoon zien dat de gekozen systematiek niet deugt.
Validering
Nu de NZa met haar getallen komt de vraag of de data wel valide zij(meten ze wel wat ze beogen te meten) en van voldoende kwaliteit. De adviescommissie pleitte eerder hier minimale normen voor te stellen. De NZa heeft de Adviescommissie daarop gevraagd zelf een voorstel voor te doen en de kwaliteitskaders te concretiseren. De adviescommissie komt daar later in 2024 op terug. Toch is het erg vreemd dat de NZa een uitspraak over de validiteit aan de adviescommissie vraagt. Ze kan daar zelf ook op basis van haar getallen en tabellen een uitspraak over doen. Je kan zo ook de rare situatie krijgen als de adviescommissie stelt dat de data niet valide zijn en de NZa toch door wil gaan met de systematiek van de zorgvraagtypering. En daarmee beweert dat ze wel (min of meer valide zijn).
Interbeoordelaarsbetrouwbaarheid
De Adviescommissie en NZa hebben vragen over de vergelijkbaarheid van zorgvraagtyperingen tussen verschillende behandelaren. Dat is een zeer terechte vraag. Het is echter niet een vraag die men zich nu pas moet gaan stellen. Men wist namelijk met de keuze van de zorgvraagtypering op basis van de antwoorden op HONOS-vragenlijsten al dat men als basis van het systeem een Routine Outcome Monitoring(ROM)vragenlijst hanteert die door verschillende beoordelaars verschillend ingevuld kan worden. Daarbij komt nog dat een groot aantal zorgverleners de HONOS-vragenlijsten helemaal niet gebruikten voor de verplichte aanlevering begon. Men vult dus verplicht lijsten in waardoor snel afvinken/afraffelen van een verplicht nummer voor de hand licht.
Algemene Rekenkamer
Al in 2017 waarschuwde de Algemene Rekenkamer(AR) de NZa al om geen ROM-vragenlijsten te gebruiken voor een nieuwe bekostigingssystematiek. Als belangrijkste bezwaren gaf de AR het per definitie subjectieve karakter van ROM-scores aan naast de onvolledigheid van de gegevensverzameling.(blz 21. van het AR-rapport) Ook de zorgvraagzwaarte-indicator, iets waaraan sinds 2013 gewerkt wordt, vond men niet zo geschikt, omdat de zeggingskracht van die indicator op patiëntniveau zeer beperkt is volgens de AR, nl maar 6,5 %. De AR stelt in hoofdstuk 4.1(blz. 33) dat zorgaanbieders aan de hand van de uitkomsten niet te vergelijken zijn. In hoofdstuk 4.2(blz. 34) zegt de AR dat haar uitkomsten in lijn zijn met een internationale studie van(Moynihan & Beazley, 2016). Deze studie geeft aan dat er een gat is tussen de wens om kwaliteitsindicatoren te gebruiken in de bekostiging en de problemen die er zijn bij het objectief en betrouwbaar vaststellen van deze indicatoren.
Voorspelkracht
De adviescommissie meldt dat uit de pilot van het zorgclustermodel bleek dat zorgvraagtypen 18,5% van de kostenspreiding (variantie) verklaren. De diagnosehoofdgroep verklaarde ongeveer 6% van de spreiding (variantie). Wanneer meerdere voorspellers werden gecombineerd (zorgvraagtype, diagnosehoofdgroep en aanvullende items uit de scorelijst) werd een verklarende variantie van 27% bereikt. Men komt nu met het advies om een soortgelijke analyse te maken o.b.v. de nieuwe data(de 500.000 binnen gekregen cliënt-data) en daarin ook combinaties te laten zien met andere voorspellers. Men zoekt naar een model dat de GGZ-zorgkosten vrij nauwkeurig kan voorspellen. Zelfs al zou men in staat zijn de voorspelkracht te verdubbelen tot 54 % dan nog zou deze enorm te kort schieten. In een artikel van Follow The Money van 21 december 2022 maakte professor Aartjan Beekman, hoogleraar psychiatrie, echter duidelijk dat nog geen procent van de verzekerden in Nederland verantwoordelijk is voor 66 procent van de GGZ-kosten.
Niet beter dan elders
Het stuk van de adviescommissie liet ik prof. J. van Os, hoogleraar psychiatrie te Utrecht, lezen. Zijn antwoord was ook duidelijk. Hij vond het, niet verbazingwekkend, precies dezelfde resultaten hebben als eerder in Australië en de Verenigd Koninkrijk. Op het zorgclustermodel uit het V.K. is het Nederlandse bedenksel van de NZa gebaseerd. Daar voerde men het systeem niet in !!!!!!!!!!!!!
Het is de vraag wanneer de NZa in gaat zien dat ze zoekt naar een heilige graal die ze nooit zal vinden.
W.J. Jongejan, 23 februari 2024

Recente reacties