Minister Helder jokt tegen Kamer in antwoord op motie Joseph
 Op 24 juni 2024 stuurde minister Helder van VWS haar antwoord op de door de Tweede Kamer op 4 juni aangenomen motie Joseph/Westerveld/Dobbe. Deze ging over de privacy/medisch beroepsgeheim schendende verzameling van antwoorden op HONOS-vragenlijsten van 800.000 GGZ-cliënten. De Nederlandse Zorgautoriteit(NZa) eiste die medio 2023 op bij GGZ-zorgaanbieders. De actiegroep Vertrouwen in de GGZ spande daarover een bodemprocedure aan tegen de NZa. Het antwoord van de minister komt erop neer dat zij de motie niet gaat uitvoeren. In de motie staan zaken die in strijd zijn met de waarheid. Met name gaat het daarbij over de aard van de gegevens die de NZa verzamelt en de herleidbaarheid ervan. De minister slalomt met omhaal van woorden om het begrip herleidbaarheid heen. Die herleidbaarheid werd door de NZa zelf bewust uit de correspondentie met de Autoriteit Persoonsgegevens gehouden toen die een oordeel moest geven over de dataverzameling.
Op 24 juni 2024 stuurde minister Helder van VWS haar antwoord op de door de Tweede Kamer op 4 juni aangenomen motie Joseph/Westerveld/Dobbe. Deze ging over de privacy/medisch beroepsgeheim schendende verzameling van antwoorden op HONOS-vragenlijsten van 800.000 GGZ-cliënten. De Nederlandse Zorgautoriteit(NZa) eiste die medio 2023 op bij GGZ-zorgaanbieders. De actiegroep Vertrouwen in de GGZ spande daarover een bodemprocedure aan tegen de NZa. Het antwoord van de minister komt erop neer dat zij de motie niet gaat uitvoeren. In de motie staan zaken die in strijd zijn met de waarheid. Met name gaat het daarbij over de aard van de gegevens die de NZa verzamelt en de herleidbaarheid ervan. De minister slalomt met omhaal van woorden om het begrip herleidbaarheid heen. Die herleidbaarheid werd door de NZa zelf bewust uit de correspondentie met de Autoriteit Persoonsgegevens gehouden toen die een oordeel moest geven over de dataverzameling.
Wat schrijft de minister?
De minister laat in de alinea ‘Uitvoering verzoek 1’weten:
“Eerder heb ik aangegeven dat tussen 1 juli 2023 en 1 december 2023 de NZa een éénmalige data-uitvraag heeft gedaan bij ggz zorgaanbieders van de HoNOS+ vragenlijsten over de periode 1 juli 2022 tot en met 30 juni 2023. Het ging om gepseudonimiseerde gegevens waarin geen tot personen herleidbare identificeerbare gegevens zitten zoals naam, Burgerservicenummer, geboortedatum, geslacht, woonplaats en postcode, informatie met data van de verblijfsdagen, zorgtrajectnummer en datum en type consult.”
Wat jokkebrokt ze hier?
De minister doet hier voorkomen dat de NZa HONOS-gegevens binnen kreeg zonder direct identificeerbare gegevens. Dat is absoluut onwaar. Op basis van Woo-stukken over de HONOS-zaak, verkregen van de NZa, blijkt dat de antwoorden op de HONOS-vragen in hun geheel , gepseudonimiseerd, binnenkwamen. NA BINNENKOMST ontdeed men de data pas van de direct identificerende data. Die laatste data noemt men de oranje data en de overblijvende data de groene dataset. De opsomming die de minister geeft van identificerende data is niet geheel toevallig. Dat zijn namelijk alle typen data die genoemd staan in de motie Hijink/Westerveld van 29 november 2022 en die de NZa niet zou mogen verwerken. De oorspronkelijke motie was veel strikter en verbood verwerking van alle gepseudonimiseerde data. Door toedoen van o.a. Joba van den Berg (CDA) kwam er een aanpassing aan de motie, met het argument het draagvlak voor aannemen te vergroten. Toen verscheen de opsomming van typen data in de motie.
Gepseudonimiseerd
Het gepseudonimiseerd zijn van gegevens betekent niet dat die data niet herleidbaar zijn tot personen. Pseudonimiseren vertraagt hooguit de herleiding tot een persoon, maar maakt het niet onmogelijk. Ook na verwijdering van direct identificerende items zijn de overblijvende data, in het NZa-geval de gepseudonimiseerde groene data, nog steeds herleidbaar. Uit de Woo-stukken afkomstig van de NZa in de HONOS-zaak blijkt dat de NZa dat zelf heel goed beseft.
Interne NZa-mails
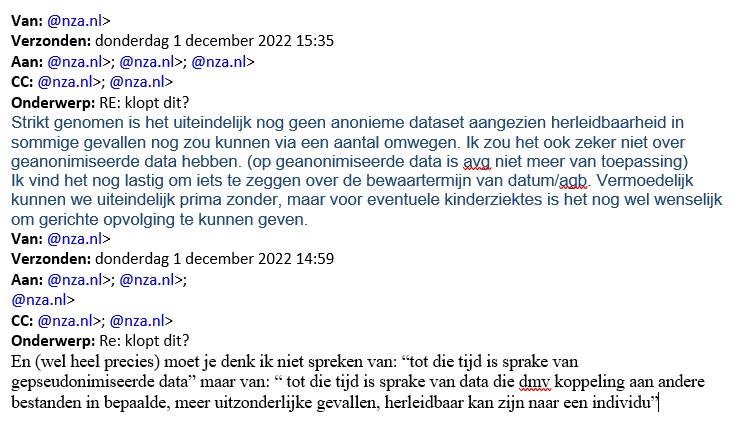
Op 10 juni 2024 schreef ik daar ook al over. In meerdere interne mails van 1 december 2022 uit de Woo-verzamellijst 3 komt uit mailverkeer binnen de NZa naar voren dat die groene lijst toch wel data bevat die, zij het met enige moeite en kennis van databases, toch wel herleidbaar kan zijn tot een persoon. Iemand van de NZa schrijft op 1 december 2022 over die groene lijst:
“Strikt genomen is het uiteindelijk nog geen anonieme dataset aangezien herleidbaarheid in sommige gevallen nog zou kunnen via een aantal omwegen.”
Men wist/weet dus dondersgoed dat de overblijvende, groene, dataset gegevens bevat die in principe herleidbaar zijn tot een persoon. Dus niet anoniem zijn. Daarmee is duidelijk dat de NZa bijzondere persoonsgegevens verzamelt/verwerkt zonder toestemming van de cliënt. Hetgeen vanwege de AVG niet mag.
Niet rechtstreeks
De NZa krijgt de data via een kleine omweg. Op 29 december 2023 schreef ik al dat de NZa gebruik maakt van het Amerikaanse bedrijf Clevr. Het was te lezen in de Woo-stukken. Dat bedrijf bouwt voor de NZa ICT-oplossingen, waaronder de tool waarin de gegevens voortkomend uit de informatieverplichting zorgvraagtypering worden aangeleverd en tijdelijk opgeslagen(in de cloud). Vermoedelijk voert Clevr op dezelfde contractbasis de scheiding uit van de direct identificerende persoonsgegevens van de rest van de data. Omdat Clevr dat werk doet in opdracht van de NZa ontvangt de NZa formeel gezien de hele dataset zelf. Nu lijkt het zo dat de NZa door het ontvangen van gestripte data zelf een kalere dataset ontvangt. Maar in werkelijkheid ligt dat anders. Uitbesteden betekent niet dat de verantwoordelijkheid ervoor verdwijnt
Suggestief
Het is nogal irritant dat door suggestief woordgebruik de minister de indruk wekt dat de NZa slechts zeer onschuldige data verwerkt. Ongetwijfeld hebben PR-/communicatie-medewerkers van de NZa
de minister in gefluisterd om zo over de data te spreken/schrijven. De minister suggereert helaas iets wat er niet is en spreekt zo onwaarheid. Iets dergelijks deed ze overigens precies zo toen ze voor de stemming middels een Kamerbrief de leden van de Tweede Kamer afraadde om voor te gaan stemmen. Ik beschreef dat op 10 juni 2024.
Als de minister Pinoccio was zou ze nu een heel lange neus hebben.
W.J. Jongejan, 26-november 2024
Afbeelding van Roland Schwerdhöfer via Pixabay

{kind=link}
Plaats een Reactie
Meepraten?Draag gerust bij!